Overview
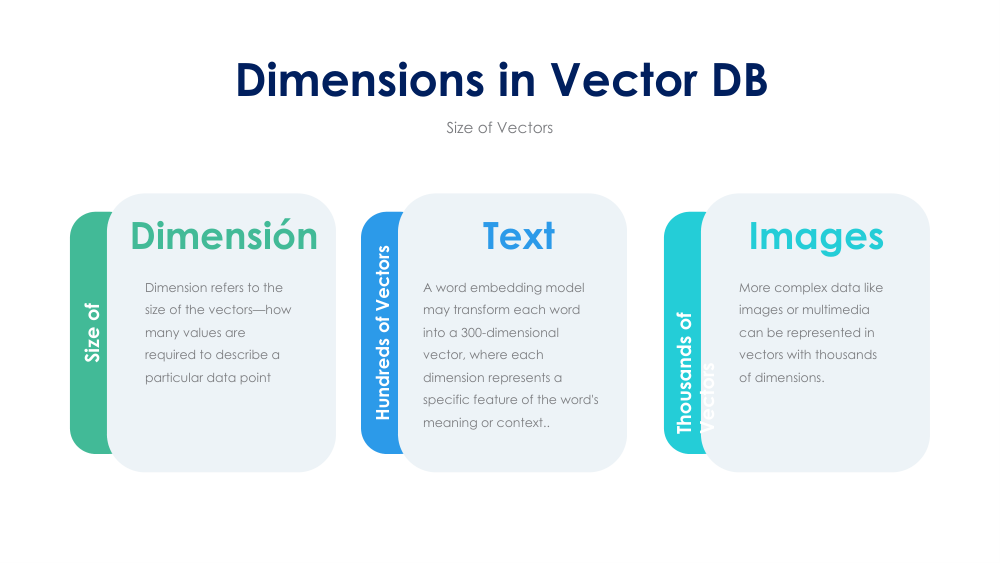
Vector databases store high-dimensional numerical representations of data. These vectors capture the meaning, structure, and relationships embedded in text, images, audio, and multimodal inputs.
The number of dimensions in a vector depends on the model that generated it. More dimensions allow more expressive representations, but also come with computational trade-offs.