CRUD Operations in Vector Databases
Understand how vector databases perform create, read, update, and delete operations, and how indexing strategies impact performance and accuracy.
Understand how vector databases perform create, read, update, and delete operations, and how indexing strategies impact performance and accuracy.
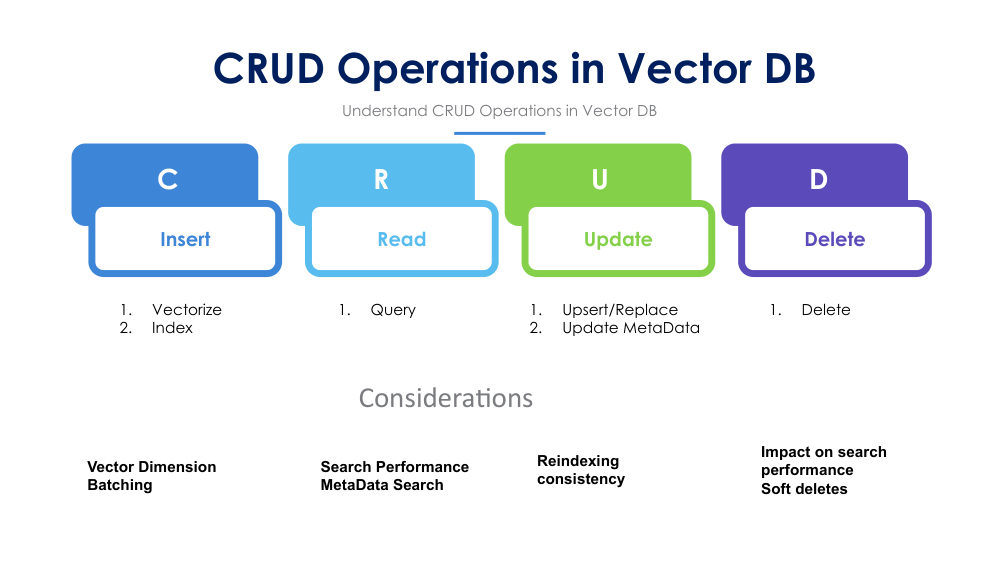
Vector databases store high‑dimensional embeddings and enable similarity search. CRUD operations behave differently than in traditional databases because embeddings require specialized indexing structures for efficient retrieval and updates.
Insert new vectors and metadata. Indexes must update incrementally to maintain search efficiency.
Search vectors using similarity metrics like cosine or Euclidean distance. Indexes accelerate nearest‑neighbor lookup.
Modify existing vectors. Some index types require full or partial rebuilds to preserve correctness.
Remove vectors and mark index entries as deleted. Background compaction may be required.
Index structures like HNSW allow incrementally adding new vectors without full rebuilds.
Indexes return approximate or exact nearest neighbors based on configuration.
Most systems treat updates as delete‑and‑reinsert operations for consistency.
Some index types mark entries as deleted and later clean up during compaction.
Query and retrieve documents by meaning instead of keyword matching.
Identify similar products, songs, or content using vector embeddings.
Store embeddings for retrieval‑augmented generation in LLM applications.
No. Some support exact search, but approximate methods are more common for performance.
Yes, depending on the index type. Some require partial rebuilds and background maintenance.
HNSW, IVF‑Flat, PQ, scalar quantization, and graph‑based ANN indexes.
Learn how CRUD operations and indexing shape performance in AI‑powered systems.
Start Learning